
This sponsored article was created by our content partner, BAW Media. Thank you for supporting the partners who make SitePoint possible.
Image optimization is a big deal when it comes to website performance. You might be wondering if you’re covering all the bases by simply keeping file size in check. In fact, there’s a lot to consider if you truly want to optimize your site’s images.
Fortunately, there are image processing tools and content delivery networks (CDNs) available that can handle all the complexities of image optimization. Ultimately, these services can save you time and resources, while also covering more than one aspect of optimization.
In this article, we’ll take a look at the impact image optimization can have on site performance. We’ll also go over some standard approaches to the problem, and explore some more advanced image processing options. Let’s get started!
Why Skimping on Image Optimization Can Be a Performance Killer
If you decide not to optimize your images, you’re essentially tying a very heavy weight to all of your media elements. All that extra weight can drag your site down a lot. Fortunately, optimizing your images trims away the unnecessary data your images might be carrying around.
If you’re not sure how your website is currently performing, you can use an online tool to get an overview.
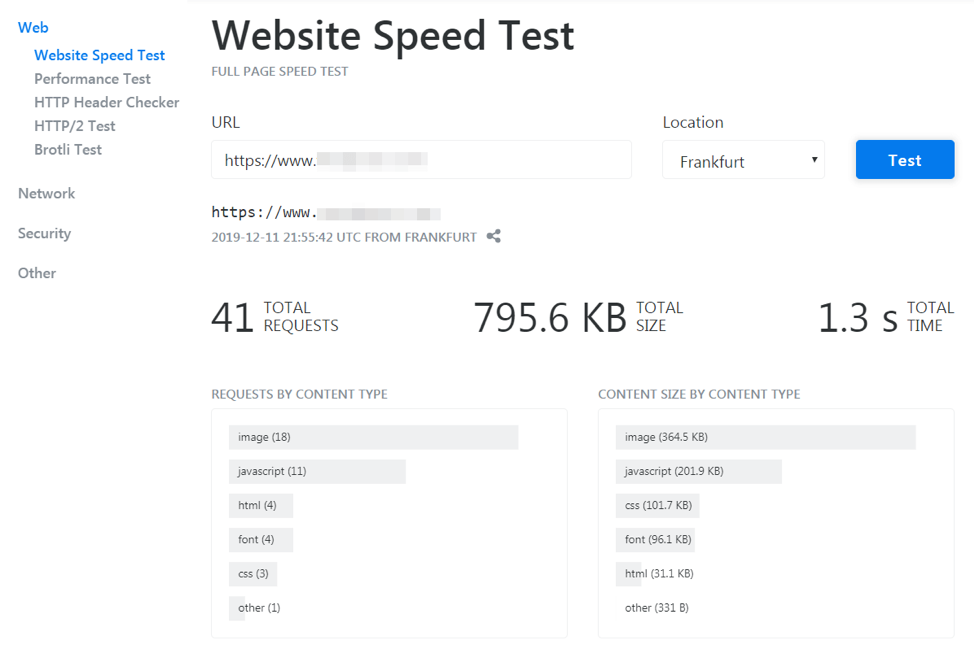
Once you have a better picture of what elements on your website are lagging or dragging you down, there are a number of ways you can tackle image optimization specifically, including:
- Choosing appropriate image formats. There are a number of image formats to choose from, and they each have their strengths and weaknesses. In general, it’s best to stick with JPEGs for photographic images. For graphic design elements, on the other hand, PNGs are typically superior to GIFs. Additionally, new image formats such as Google’s WebP have promising applications, which we’ll discuss in more detail later on.
- Maximizing compression type. When it comes to compression, the goal is to get each image to its smallest “weight” without losing too much quality. There are two kinds of compression that can do that: “lossy” and “lossless”. A lossy image will look similar to the original, but with some decrease in quality, whereas a lossless image is nearly indistinguishable from the original but also heavier.
- Designing with the image size in mind. If you’re working with images that need to display in a variety of sizes, it’s best to provide all the sizes you’ll need. If your site has to resize them on the fly, that can negatively impact speeds.
- Exploring delivery networks. CDNs can be a solution to more resource-heavy approaches for managing media files. A CDN can handle all of your image content, and respond to a variety of situations to deliver the best and most optimized files.
As with any technical solution, you’ll have to weigh the pros and cons of each approach. However, it’s also worth noting that these more traditional approaches aren’t the only options you have available to you.
4 Reasons to Use Image Processing for Optimizing Your Website’s Media
As we
Truncated by Planet PHP, read more at the original (another 2853 bytes)