Together with our clients, we want to maximise our impact on sustainable development. We distinguish between the impact on people and the environment resulting from within Liip, and from the projects that we implement. So the HOW and the WHAT. We wrote extensively about the HOW last year.
What are Sustainable Development Goals?
In 2015, the UN adopted the Sustainable Development Goals. The 17 goals set out the key areas of the social, environmental and economic sustainable development that the global community seeks to achieve. Examples include measures on climate action (13) or protecting life below water (14) and on land (15).
We opted for the internationally broadly supported SDGs,because the current proliferation of tools and labels are obstacles more than help. There is currently no single standard, as has been in place for decades for financial accounting, for example.
So that we do not lose an opportunity, we are using the SDGs to collect impact data at a very high level of granularity across all aspects of sustainability.
What exactly are we measuring?
How does the project affect the SDGs? Which SDGs more than others? And what about the company behind it: is there a clear, mandatory message regarding its impact on humans and the environment? We have assigned a percentage weighting to the individual goals. For example, topics such as species protection (14/15) or climate action (13) are weighted much more heavily for a food producer than they would be for a training company.
We then take a look at how strongly connected the project is with the company’s activities. Does the project represent the client’s main area of activity, or is it far removed from its core business? The project’s classification may be congruent with the company, may be separate, or may be a mixture of both.
For each individual aspect, we rate the contribution to a specific sustainability goal on a scale of -2 to +2. We use objective, measurable criteria wherever possible. For example, has a company made a clear and verifiable statement using recognised methods regarding if and how it expects to achieve the climate targets from the Paris Agreement?

Figure 1: Relevance and impact assessment of the individual UN goals of the client project
Of course, there are also assessments for which we lack the data basis. This is a weak point, and we will try to cross-check with recognised agencies wherever possible, especially for large-scale projects.

Figure 2: Sustainability impact of a customer product, composed of company impact (here 80%) and project impact (here 20%)
And how well are we performing?
Our first ‘inventory’ offered a fundamentally good result. Most projects are positively contributing to the SDGs, respectively do not produce any demonstrable damage. This is also thanks to the fact that we have consistently rejected critical projects ever since the company was founded – for example, any projects related to oil production or conflict materials. We are therefore beginning the measurement with a ‘beneficial’ portfolio. Due to the fact that the topic of biodiversity as a whole still receives far too little attention in the economy. This also influences our portfolio. We will pay special attention to this goal.
We now have an overall picture of our activities. This enables us to prioritise specific goals that are not doing so well more strategically.To keep it simple, we multiply the hours worked on a project by the impact on a goal. Admittedly, this is rather imprecise, but it is still meaningful for us because it gives us an indicator of what we are spending our time on in the first place.
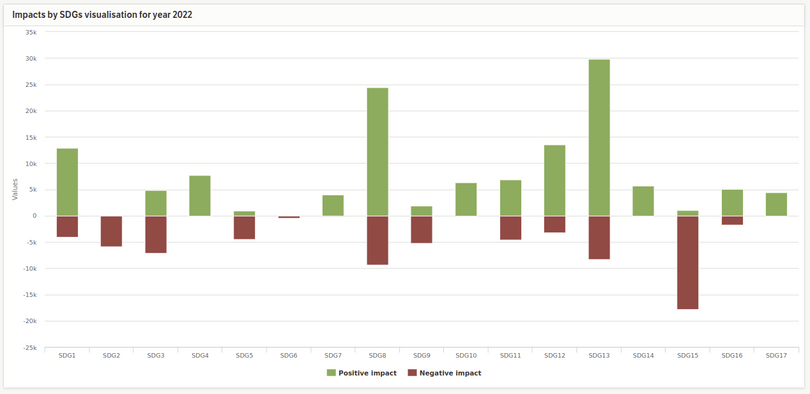
Figure 3: Effect of hours worked for clients per SDG
Is this just greenwashing?
There are currently huge amounts of activity relating to impact measurement. And much of this is marginal. Sustainability is currently in fashion, and often things that are brown and unfair are painted green and put in a social light. Because we are aware of this, we are operating as cautiously as possible by setting broad system limits, and by drawing on a holistic metric with the SDGs. And, in the event of doubt, we make a more conservative assessment to avoid a false sense of security. As a point of principle, we obtain publicly available evidence and statements from companies wherever these are available.
What is the next step?
We plan to take this chosen approach
Truncated by Planet PHP, read more at the original (another 517 bytes)

